
大六壬预测实例集合 速度超Mask RCNN4倍,仅在单个GPU训练的实时实例分割算法 | 技术头条
大六壬预测实例集合 速度超Mask RCNN4倍,仅在单个GPU训练的实时实例分割算法 | 技术头条
制作 |人工智能技术大本营(id:)
【简介】在论文“:Real-time”中,作者提出了一种简洁的实时实例分割全卷积模型,仅使用单个Titan Xp,在MS COCO上以33 fps实现29. 8 mAP,速度明显优于以往现有算法。而且这个结果是在单GPU上训练得到的!
简介
一开始,作者问了一个问题:创建实时实例分割算法需要什么?
在过去的几年里,实例分割取得了很大进展,部分原因是借用了与对象检测领域相关的技术。例如,掩模 RCNN 和 FCIS 等实例分割方法直接构建在 R-CNN 和 R-FCN 等对象检测方法之上。然而,这些方法主要关注图像性能,而关注实时性能的SSD、YOLO等实例分割算法却很少见。因此,本文的工作主要是填补这一空白。 SSD的方法就是简单的去掉Two-Stage变成One-Stage方法,然后用其他方法来弥补性能上的损失。然而,在实例分割领域推广此类方法并不容易,因为二阶段方法高度依赖特征定位来生成掩码,并且此类方法是不可逆的。 One-Stage方法,比如FCIS,也不能做到实时,因为后期需要大量的处理。
简介
基于此,作者在本研究中提出了一种放弃特征定位的方法——(You Only Look At)来解决实时性问题。
将实例分割分解为两个并行任务:(1)在整个图像上生成一个非局部原型掩码字典;(2)为每个实例预测一组线性组合系数。从从这两部分生成全图实例分割的想法很简单:对于每个实例,使用预测系数对原型进行线性组合大六壬预测实例集合,然后使用预测的边界框进行裁剪。这样,作者让网络学习如何定位实例掩码本身大六壬预测实例集合 速度超Mask RCNN4倍,仅在单个GPU训练的实时实例分割算法 | 技术头条,这些在视觉、空间和语义上相似的实例在原型中是不同的。
作者发现大六壬预测实例集合 速度超Mask RCNN4倍,仅在单个GPU训练的实时实例分割算法 | 技术头条,由于这个过程不依赖于 ,所以这种方法产生了高质量和动态稳定性的掩码。尽管本文使用全卷积网络实现,但模板掩码可以通过平移转换自行定位实例。最后,作者还提出了 Fast NMS,它比标准 NMS 快 12ms,性能损失很小。
这种方法具有三个优点:
首先,它非常快。
其次,由于没有使用“”之类的方法,所以遮罩的质量非常高。
第三,这个想法可以概括。可以将生成原型和掩码系数的思想添加到现有的物体检测算法中。
算法
算法介绍
为了提高实例分割的速度,作者提出了一种快速的、单阶段的实例分割模型——.主要思想是将Mask分支添加到单阶段对象检测框架中。因此,研究人员将实例分割任务分解为两个更简单的并行任务,将它们组合起来形成最终的 Mask。网络结构图如下图所示。
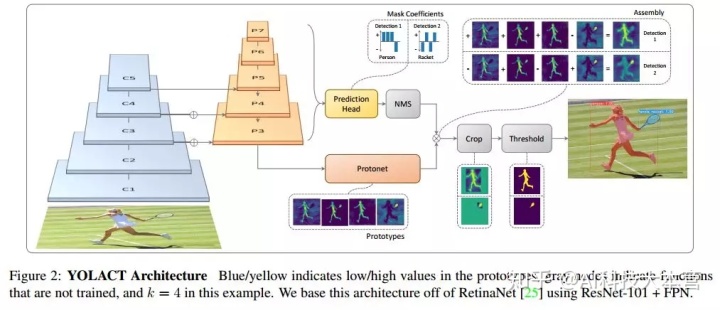
作者将复杂的实例分割任务分解为两个更简单的并行任务大六壬预测实例集合,可以组合形成最终的掩码。第一个分支使用 FCN 生成一组不依赖任何实例的图像大小的“掩码”。第二个是在目标检测分支中添加一个额外的头,用于预测每个 的“掩码系数”(掩码)向量,其中是编码原型空间中的实例表示。最后,对于 NMS 之后的每个实例,我们通过将两个分支线性组合为该实例构造一个掩码。
将问题分解为两个平行的部分,利用 fc 层(擅长产生语义向量)和 conv 层(擅长产生空间连贯的掩模)分别产生“掩模系数”和“原型掩模”。由于原型和掩码系数可以独立计算,检测器的计算开销主要来自于综合()步骤,可以实现为单个矩阵乘法。这样,论文中的方法可以在保持特征空间的空间一致性的同时,仍然是 One-Stage 和快速的。
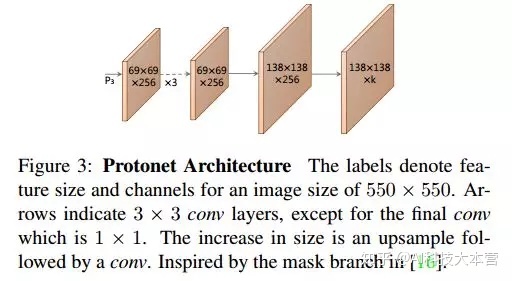
原型生成分支是一组 K 个原型掩码,用于预测整个图像。采用 FCN 实现,其最后一层有 k(每个原型一个)并将其附加到特征层。
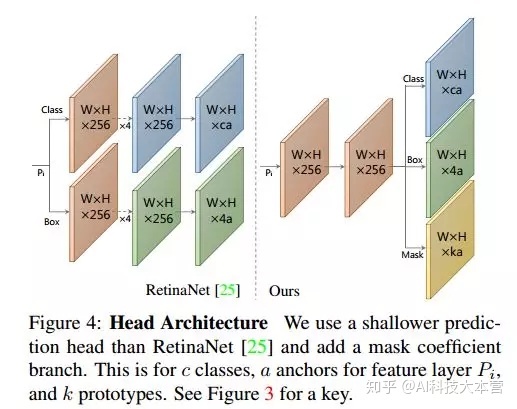
在实验中,每次预测都是(4+C+k)个值,额外的k个值就是mask系数。此外,为了通过线性组合得到掩模,一个重要的步骤是从最终掩模中减去原型掩模。换句话说,掩码系数必须是正的和负的。因此,在mask系数预测中使用tanh函数进行非线性激活,因为tanh函数的取值范围是(-1,1).
为了生成实例掩码,两个分支的输出经过基本矩阵乘法和函数处理以合成掩码。
其中,P为h×w×k的原型掩码集; C是n×k的系数集,代表n个经过NMS和阈值过滤的实例,每个实例对应k个mask系数。
损失设计:损失由三部分组成:分类损失、边界框回归损失和掩模损失。分类损失和边界框回归损失与SSD相同,而掩模损失是预测掩模和真值掩模的像素级二元交叉熵。
Mask :为了提高小目标的分割效果,会先根据检测框对进行裁剪,然后进行阈值化。训练时使用真值框进行裁剪,通过除以对应的真值框面积来平衡损失尺度。
在实例分割任务中,经常需要添加转移方差。唯一添加转换方差的地方是使用预测框裁剪地图时。但这只是为了提高小目标的分割效果。笔者发现对于大中型目标,不裁剪的效果非常好。
由于预测一组原型掩码和掩码系数是一项相对困难的任务,需要更丰富、更高级的特征,因此作者希望在网络设计中兼顾速度和特征丰富度。因此,主干检测器的设计遵循了思路,同时更加注重速度。使用-101结合FPN作为默认主干网络,默认输入图像大小为550×550,如上图。使用-L1 loss训练box参数,使用和SSD一样的box参数编码。使用交叉熵训练分类部分,一共有(C+1)个类别。同时采用OHEM方法选择训练样本,正负样本比例设置为1:< @3. 值得注意的是focal不是用的一样,loss。
一个。计算每个类别前n个框的IOU,得到C*n*n的矩阵X(对角矩阵),对每个类别的框进行降序排序。
b.其次,通过检查任何得分较高的框的IOU是否大于某个阈值来找到要删除的框,方法是将X的下三角和对角线区域设置为0。这可以在批量上三角剖分中实现,然后保持按列的最大值计算每个检测器的最大 IOU 矩阵 K。
c。最后,使用阈值 t (K
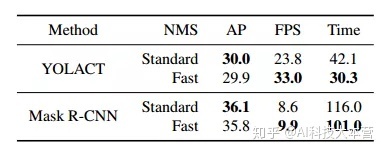
论文实验
作者在 MS COCO 测试开发数据集上比较了当前最先进方法的性能。本文的重点是提高速度,所有实验都是在 Titan Xp 上进行的,因此有些结果可能与原论文略有不同。
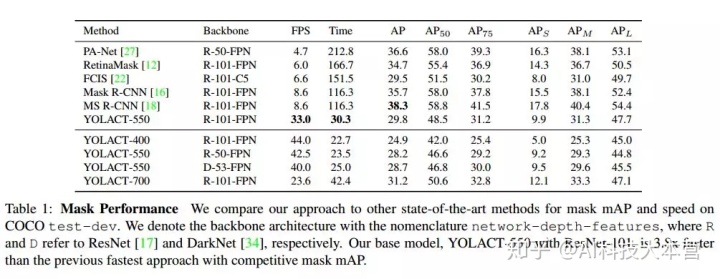
在不同大小的输入图像的情况下验证我们模型的性能的实验。除了基本的 550×550 模型外,还有输入为 400×400 和 700×700 的模型,它们会相应地调整大小(sx=s550/550*x s)。减小图像尺寸会导致性能显着下降,也就是说图像越大,实例分割的性能越好,但增加图像尺寸会降低运行速度,同时提高性能。
当然,作者也对Mask质量和视频动态稳定性做了对比实验,详细分析了优劣。详情见论文。
总结
网络的优势:快速、高质量的掩码、出色的动态稳定性。
网络的缺点:性能略低于目前最好的实例分割方法,检测、分类错误和边界框位移等导致的错误很多。
另外,作者在最后还提到了这种方法的一些典型错误:
1)定位错误:当场景中的某个点有多个目标时,网络可能无法在自己的模板中定位到每个对象,会输出一些类似于前景蒙版的对象这次。而不是在这组实例中分割出一些对象。
2) leak():网络修剪预测的集成掩码,但不对输出进行去噪。这样,当b-box准确时,它没有任何作用,但是当b-box不准确时,噪声会被带入 mask大六壬预测实例集合,造成一些“泄漏”。
解读到此告一段落,感兴趣的朋友可以在下方地址阅读原文